Los nodos manejan tablas de encaminamiento, en las que aparece la ruta que deben seguir los paquetes con destino a un nodo determinado de la red.
Podemos distinguir entre encaminamiento salto a salto y encaminamiento fijado en origen. Nosotros veremos con detalle sólo el primer tipo (salto a salto).
9.2.2.1. Encaminamiento salto a salto
En la literatura inglesa, este tipo de encaminamiento se denomina como hop by hop. Se basa en que cada nodo no tiene que conocer la ruta completa hasta el destino, sino que sólo debe saber cuál es el siguiente nodo al que tiene que mandar el paquete: las tablas dan el nodo siguiente en función del destino. Como ejemplo, tomemos la siguiente red:
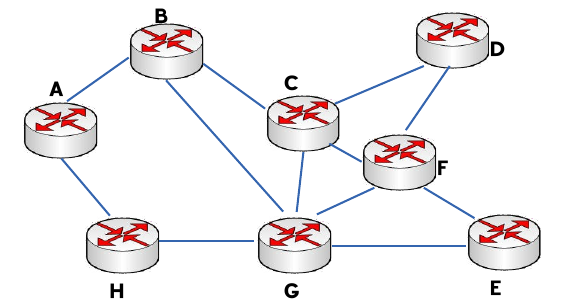
Red de ejemplo
Las tablas de encaminamiento de los nodos A y B serán:
| Tabla de encaminamiento del nodo A | Tabla de encaminamiento del nodo B | ||
|---|---|---|---|
| Destino | Siguiente nodo | Destino | Siguiente nodo |
| B | B | A | A |
| C | B | C | C |
| D | B | D | C |
| E | H | E | C |
| F | H | F | C |
| G | H | G | G |
| H | H | H | A |
En la tabla de encaminamiento de cada nodo deberá aparecer una entrada en el campo destino por cada nodo que se pueda alcanzar desde el citado nodo, y en el campo siguiente nodo aparecerá el nodo vecino al que se deberá enviar los datos para alcanzar el citado nodo destino. Las soluciones propuestas no son únicas, pudiendo elegir otros caminos que minimicen el tiempo de retardo, el número de saltos, etc. La única condición que se impone es que debe haber consistencia: si, por ejemplo, para ir de A a B pasamos por C, entonces para ir de B a C no podremos pasar por A, porque entonces se formaría un bucle y el paquete mandado estaría continuamente viajando entre los nodos B y A, como puede comprobarse fácilmente.
9.2.2.2. Encaminamiento fijado en origen
En inglés este encaminamiento se llama source routing. En él, son los sistemas finales los que fijan la ruta que ha de seguir cada paquete. Para ello, cada paquete lleva un campo que especifica su ruta(campo RI: Routing Information), y los nodos sólo se dedican a reenviar los paquetes por esas rutas ya especificadas. Así pues, son los sistemas finales los que tienen las tablas de encaminamiento y no se hace necesaria la consulta o existencia de tablas de encaminamiento en los nodos intermedios. Este tipo de encaminamiento suele ser típico de las redes de IBM.
| Tabla de encaminamiento del nodo A | Tabla de encaminamiento del nodo B | ||
|---|---|---|---|
| Destino | Ruta a seguir | Destino | Ruta a seguir |
| B | B | A | A |
| C | B-C | C | C |
| D | B-C-D | D | C-D |
| E | H-G-E | E | C-F-E |
| F | H-G-F | F | C-F |
| G | H-G | G | G |
| H | H | H | A-H |
9.2.2.3. Comparación entre ambos tipos de encaminamiento
Lo veremos por medio de la siguiente tabla:
|
|
Fijado en Origen | Salto a Salto |
|---|---|---|
| Conocimiento | Los sistemas finales han de tener un conocimiento completo de la red | SIMPLICIDAD: Los nodos han de tener un conocimiento parcial de la red (saber qué rutas son las mejores) |
| Complejidad | Recae toda en los sistemas finales | En los sistemas intermedios ya que son los que tienen que encaminar |
| Problemas de Bucles | No hay bucles: el sistema final fija la ruta (ROBUSTEZ) | Sí pueden ocurrir: no se tiene una visión completa de la red (INCONSISTENCIA) |
Los bucles (situación que se da cuando los paquetes pasan más de una vez por un nodo) ocurren porque los criterios de los nodos no son coherentes, generalmente debido a que los criterios de encaminamiento o no han convergido después de un cambio en la ruta de un paquete; cuando por cualquier causa un paquete sufre un cambio de encaminamiento, la red tarda en adaptarse a ese cambio pues la noticia del cambio tiene que llegar a todos los nodos. Es en ese transitorio cuando se pueden dar los bucles, ya que unos nodos se han adaptado y otros no. El objetivo de los algoritmos de encaminamiento es detener el curso de los paquetes antes de que se produzcan bucles. Esto es importante sobre todo cuando se envían los paquete s por varias rutas simultáneamente (técnicas de inundación, etc…).