IP es el principal protocolo de la capa de red. Este protocolo define la unidad básica de transferencia de datos entre el origen y el destino, atravesando toda la red de redes. Además, el software IP es el encargado de elegir la ruta más adecuada por la que los datos serán enviados. Se trata de un sistema de entrega de paquetes (llamados datagramas IP) que tiene las siguientes características:
- Es no orientado a conexión debido a que cada uno de los paquetes puede seguir rutas distintas entre el origen y el destino. Entonces pueden llegar duplicados o desordenados.
- Es no fiable porque los paquetes pueden perderse, dañarse o llegar retrasados.
Nota
El protocolo IP está definido en la RFC 791
3.2.1.1. Formato del datagrama IP
El datagrama IP es la unidad básica de transferencia de datos entre el origen y el destino. Viaja en el campo de datos de las tramas físicas (recuérdese la trama Ethernet) de las distintas redes que va atravesando. Cada vez que un datagrama tiene que atravesar un router, el datagrama saldrá de la trama física de la red que abandona y se acomodará en el campo de datos de una trama física de la siguiente red. Este mecanismo permite que un mismo datagrama IP pueda atravesar redes distintas: enlaces punto a punto, redes ATM, redes Ethernet, redes Token Ring, etc. El propio datagrama IP tiene también un campo de datos: será aquí donde viajen los paquetes de las capas superiores.
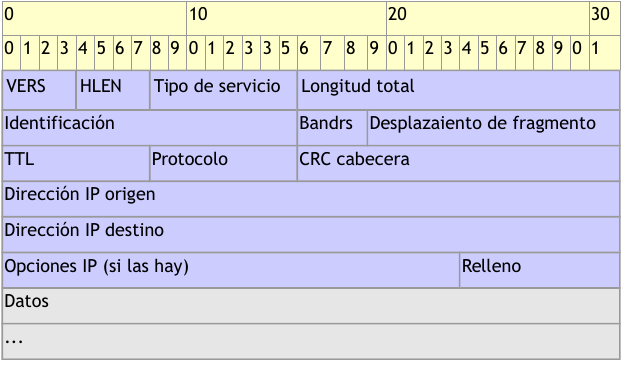
Campos del datagrama IP
- VERS (4 bits). Indica la versión del protocolo IP que se utilizó para crear el datagrama. Actualmente se utiliza la versión 4 (IPv4) aunque ya se están preparando las especificaciones de la siguiente versión, la 6 (IPv6).
- HLEN (4 bits). Longitud de la cabecera expresada en múltiplos de 32 bits. El valor mínimo es 5, correspondiente a 160 bits = 20 bytes.
- Tipo de servicio (Type Of Service). Los 8 bits de este campo se dividen a su vez en:
- Prioridad (3 bits). Un valor de 0 indica baja prioridad y un valor de 7, prioridad máxima.
- Los siguientes tres bits indican cómo se prefiere que se transmita el mensaje, es decir, son sugerencias a los encaminadores que se encuentren a su paso los cuales pueden tenerlas en cuenta o no.
- Bit D (Delay). Solicita retardos cortos (enviar rápido).
- Bit T (Throughput). Solicita un alto rendimiento (enviar mucho en el menor tiempo posible).
- Bit R (Reliability). Solicita que se minimice la probabilidad de que el datagrama se pierda o resulte dañado (enviar bien).
- Los siguiente dos bits no tienen uso.
- Longitud total (16 bits). Indica la longitud total del datagrama expresada en bytes. Como el campo tiene 16 bits, la máxima longitud posible de un datagrama será de 65535 bytes.
- ** Identificación (16 bits)**. Número de secuencia que junto a la dirección origen, dirección destino y el protocolo utilizado identifica de manera única un datagrama en toda la red. Si se trata de un datagrama fragmentado, llevará la misma identificación que el resto de fragmentos.
- Banderas o indicadores (3 bits). Sólo 2 bits de los 3 bits disponibles están actualmente utilizados. El bit de Más fragmentos (MF) indica que no es el último datagrama. Y el bit de No fragmentar (NF) prohíbe la fragmentación del datagrama. Si este bit está activado y en una determinada red se requiere fragmentar el datagrama, éste no se podrá transmitir y se descartará.
- Desplazamiento de fragmentación (13 bits). Indica el lugar en el cual se insertará el fragmento actual dentro del datagrama completo, medido en unidades de 64 bits. Por esta razón los campos de datos de todos los fragmentos menos el último tienen una longitud múltiplo de 64 bits. Si el paquete no está fragmentado, este campo tiene el valor de cero.
- Tiempo de vida o TTL (8 bits). Número máximo de segundos que puede estar un datagrama en la red de redes. Cada vez que el datagrama atraviesa un router se resta 1 a este número. Cuando llegue a cero, el datagrama se descarta y se devuelve un mensaje ICMP de tipo «tiempo excedido» para informar al origen de la incidencia.
- Protocolo (8 bits). Indica el protocolo utilizado en el campo de datos: 1 para ICMP, 2 para IGMP, 6 para TCP y 17 para UDP.
- CRC cabecera (16 bits). Contiene la suma de comprobación de errores sólo para la cabecera del datagrama. La verificación de errores de los datos corresponde a las capas superiores.
- Dirección origen (32 bits). Contiene la dirección IP del origen.
- Dirección destino (32 bits). Contiene la dirección IP del destino.
- Opciones IP. Este campo no es obligatorio y especifica las distintas opciones solicitadas por el usuario que envía los datos (generalmente para pruebas de red y depuración).
- Relleno. Si las opciones IP (en caso de existir) no ocupan un múltiplo de 32 bits, se completa con bits adicionales hasta alcanzar el siguiente múltiplo de 32 bits (recuérdese que la longitud de la cabecera tiene que ser múltiplo de 32 bits).
3.2.1.2. Fragmentación
Ya hemos visto que las tramas físicas tienen un campo de datos y que es aquí donde se transportan los datagramas IP. Sin embargo, este campo de datos no puede tener una longitud indefinida debido a que está limitado por el diseño de la red. El MTU de una red es la mayor cantidad de datos que puede transportar su trama física. El MTU de las redes Ethernet es 1500 bytes y el de las redes Token-Ring, 8192 bytes. Esto significa que una red Ethernet nunca podrá transportar un datagrama de más de 1500 bytes sin fragmentarlo.
Un encaminador (router) fragmenta un datagrama en varios si el siguiente tramo de la red por el que tiene que viajar el datagrama tiene un MTU inferior a la longitud del datagrama. Veamos con el siguiente ejemplo cómo se produce la fragmentación de un datagrama.
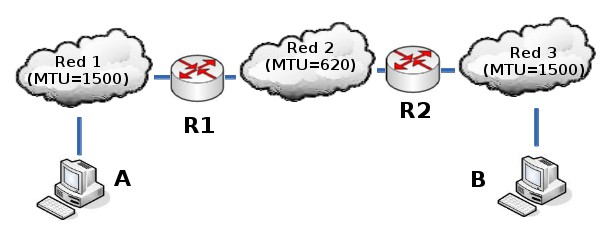
Supongamos que el host A envía un datagrama de 1400 bytes de datos (1420 bytes en total) al host B. El datagrama no tiene ningún problema en atravesar la red 1 ya que 1420 < 1500. Sin embargo, no es capaz de atravesar la red 2 (1420 >= 620). El router R1 fragmenta el datagrama en el menor número de fragmentos posibles que sean capaces de atravesar la red 2. Cada uno de estos fragmentos es un nuevo datagrama con la misma Identificación pero distinta información en el campo de Desplazamiento de fragmentación y el bit de Más fragmentos (MF). Veamos el resultado de la fragmentación:
Fragmento 1: Long. total = 620 bytes; Desp = 0; MF=1 (contiene los primeros 600 bytes de los datos del datagrama original)
Fragmento 2: Long. total = 620 bytes; Desp = 600; MF=1 (contiene los siguientes 600 bytes de los datos del datagrama original)
Fragmento 3: Long. total = 220 bytes; Desp = 1200; MF=0 (contiene los últimos 200 bytes de los datos del datagrama original)
El router R2 recibirá los 3 datagramas IP (fragmentos) y los enviará a la red 3 sin reensamblarlos. Cuando el host B reciba los fragmentos, recompondrá el datagrama original. Los encaminadores intermedios no reensamblan los fragmentos debido a que esto supondría una carga de trabajo adicional, a parte de memorias temporales. Nótese que el ordenador destino puede recibir los fragmentos cambiados de orden pero esto no supondrá ningún problema para el reensamblado del datagrama original puesto que cada fragmento guarda suficiente información.
Si el datagrama del ejemplo hubiera tenido su bit No fragmentar (NF) a 1, no hubiera conseguido atravesar el router R1 y, por tanto, no tendría forma de llegar hasta el host B. El encaminador R1 descartaría el datagrama.
3.2.1.3. CIDR ( Classless Inter-Domain Routing)
Encaminamiento Inter-Dominios sin Clases
Pronunciado como «cider» or «cedar», se introdujo en 1993 y representa la última mejora en el modo como se interpretan las direcciones IP. Su introducción permitió una mayor flexibilidad al dividir rangos de direcciones IP en redes separadas. De esta manera permitió:
Un uso más eficiente de las cada vez más escasas direcciones IPv4. Un mayor uso de la jerarquía de direcciones (“agregación de prefijos de red”), disminuyendo la sobrecarga de los enrutadores principales de Internet para realizar el encaminamiento. Los bloques CIDR IPv4 se identifican usando una sintaxis similar a la de las direcciones IPv4: cuatro números decimales separados por puntos, seguidos de una barra de división y un número de 0 a 32; A.B.C.D/N. El número tras la barra es la longitud de prefijo, contando desde la izquierda, y representa el número de bits comunes a todas las direcciones incluidas en el bloque CIDR.
Decimos que una dirección IP está incluida en un bloque CIDR, y que encaja con el prefijo CIDR, si los N bits iniciales de la dirección y el prefijo son iguales. Por tanto, para entender CIDR es necesario visualizar la dirección IP en binario. Dado que la longitud de una dirección IPv4 es fija, de 32 bits, un prefijo CIDR de N-bits deja 32 − N bits sin encajar, y hay 2(32 − N) combinaciones posibles con los bits restantes. Esto quiere decir que 2(32 − N) direcciones IPv4 encajan en un prefijo CIDR de N-bits.
Nótese que los prefijos CIDR cortos (números cercanos a 0) permiten encajar un mayor número de direcciones IP, mientras que prefijos CIDR largos (números cercanos a 32) permiten encajar menos direcciones IP. CIDR también se usa con direcciones IPv6, en las que la longitud del prefijo varia desde 0 a 128, debido a la mayor longitud de bit en las direcciones, con respecto a IPv4. En el caso de IPv6 se usa una sintaxis similar a la comentada: el prefijo se escribe como una dirección IPv6, seguida de una barra y el número de bits significativos.
CIDR usa máscaras de subred de longitud variable (VLSM) para asignar direcciones IP a subredes de acuerdo a las necesidades de cada subred. De esta forma, la división red/host puede ocurrir en cualquier bit de los 32 que componen la dirección IP. Este proceso puede ser recursivo, dividiendo una parte del espacio de direcciones en porciones cada vez menores, usando máscaras que cubren un mayor número de bits.
Las direcciones de red CIDR/VLSM se usan a lo largo y ancho de la Internet pública, y en muchas grandes redes privadas. El usuario normal no ve este uso puesto en práctica, al estar en una red en la que se usarán, por lo general, direcciones de red privadas recogidas en el RFC 1918. El término VLSM (Variable Lenght Subnet Mask - Máscara de Subred de Longitud Variable) se usa generalmente cuando se habla de redes privadas, mientras que CIDR se usa cuando se habla de Internet (red pública).
3.2.1.4. Tabla de conversión de prefijos CIDR
| CIDR | Clase | Hosts [1] | Máscara |
|---|---|---|---|
| /32 | 1/256 C | 1 | 255.255.255.255 |
| /31 | 1/128 C | 2 | 255.255.255.254 |
| /30 | 1/64 C | 4 | 255.255.255.252 |
| /29 | 1/32 C | 8 | 255.255.255.248 |
| /28 | 1/16 C | 16 | 255.255.255.240 |
| /27 | 1/8 C | 32 | 255.255.255.224 |
| /26 | 1/4 C | 64 | 255.255.255.192 |
| /25 | 1/2 C | 128 | 255.255.255.128 |
| /24 | 1 C | 256 | 255.255.255.000 |
| /23 | 2 C | 512 | 255.255.254.000 |
| /22 | 4 C | 1024 | 255.255.252.000 |
| /21 | 8 C | 2048 | 255.255.248.000 |
| /20 | 16 C | 4096 | 255.255.240.000 |
| /19 | 32 C | 8192 | 255.255.224.000 |
| /18 | 64 C | 16384 | 255.255.192.000 |
| /17 | 128 C | 32768 | 255.255.128.000 |
| /16 | 256 C, 1 B | 65536 | 255.255.000.000 |
| /15 | 512 C, 2 B | 131072 | 255.254.000.000 |
| /14 | 1024 C, 4 B | 262144 | 255.252.000.000 |
| /13 | 2048 C, 8 B | 524288 | 255.248.000.000 |
| /12 | 4096 C, 16 B | 1048576 | 255.240.000.000 |
| /11 | 8192 C, 32 B | 2097152 | 255.224.000.000 |
| /10 | 16384 C, 64 B | 4194304 | 255.192.000.000 |
| /9 | 32768 C, 128B | 8388608 | 255.128.000.000 |
| /8 | 65536 C, 256B, 1 A | 16777216 | 255.000.000.000 |
| /7 | 131072 C, 512B, 2 A | 33554432 | 254.000.000.000 |
| /6 | 262144 C, 1024 B, 4 A | 67108864 | 252.000.000.000 |
| /5 | 524288 C, 2048 B, 8 A | 134217728 | 248.000.000.000 |
| /4 | 1048576 C, 4096 B, 16 A | 268435456 | 240.000.000.000 |
| /3 | 2097152 C, 8192 B, 32 A | 536870912 | 224.000.000.000 |
| /2 | 4194304 C, 16384 B, 64 A | 1073741824 | 192.000.000.000 |
| /1 | 8388608 C, 32768 B, 128 A | 2147483648 | 128.000.000.000 |
| [1] | En la práctica hay que restar 2 a este número. La dirección menor (más baja - todos los bits de host a 0) del bloque se usa para identificar a la propia red (toda la red), y la dirección mayor (la más alta - todos los bits de host a 1) se usa como dirección de broadcast. Por tanto, en un bloque CIDR /24 podríamos disponer de 28 − 2 = 254 direcciones IP para asignar a dispositivos. |
Otro beneficio de CIDR es la posibilidad de agregar prefijos de encaminamiento, un proceso conocido como «supernetting». Una dirección IP puede encajar en varios prefijos CIDR de longitudes diferentes. Por ejemplo, dieciséis redes /24 contíguas pueden ser agregadas y publicadas en los enrutadores de Internet como una sola ruta /20 (si los primeros 20 bits de sus respectivas redes coinciden). Dos redes /20 contiguas pueden ser agregadas en una /19, etc…
Esto permite una reducción significativa en el número de rutas que los enrutadores en Internet tienen que conocer (y una reducción de memoria, recursos, etc…) y previene una explosión de tablas de encaminamiento, que podría sobrecargar a los routers e impedir la expansión de Internet en el futuro.
3.2.1.5. Superredes
Para muchas organizaciones una dirección de red de clase C es poco.
Solución: Agrupar direcciones consecutivas (tienen un prefijo común) de redes de clase C para asignarlas a una organización.
Esto permite asignar espacio de direcciones a organizaciones con redes de tamaño medio, evitando utilizar direcciones de clase B.
Ejemplo de agrupamiento:
193.40.128.0 = 11000001 00101000 1000 0000 00000000
193.40.129.0 = 11000001 00101000 1000 0001 00000000
.
.
.
193.40.142.0 = 11000001 00101000 1000 1110 00000000
193.40.143.0 = 11000001 00101000 1000 1111 00000000
La dirección de red/máscara sería 193.40.128.0/20 ( 255.255.240.0)
Máscara en binario: 11111111 11111111 11110000 00000000.
Existen 212-2 (4096-2) direcciones IP para hosts